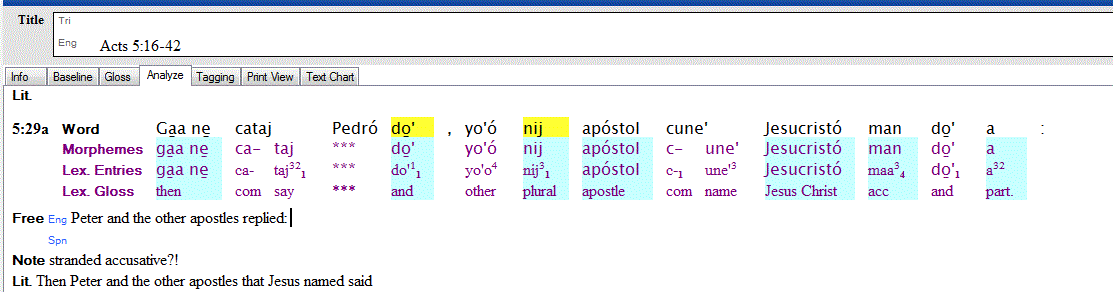
My friend Danny asked me a question about morpheme types in FLEx that prompted some thought. FLEx allows you to specify a pretty wide range of morpheme types, including a distinction between roots and stems.
The documentation resources that come with FLEx describe the distinction in the following terms:



The documentation resources that come with FLEx describe the distinction in the following terms:

I can imagine that there are projects where the root/stem distinction has some practical application, but I have not found much use for it my own work.
I don't use the automatic parsing function of FLEx, so I do manual parsing instead. Possibly something in the set-up of project with morphological rules might want the rules to be sensitive to whether affixes attach to roots vs stems.
Apart from that, it has seemed to me like I have been able to do pretty much everything I need without really using the distinction very much.
For my own purposes, I use 'stem' for nearly everything, and 'compound' for most of the rest and 'bound stem' for a small number of morphemes that appear in compounds but not independently. The possible advantage of 'stem' as the default, is that you can use the 'Components' field to show when stems contain other morphemes.
These two screen shots show the Triqui verbs achén 'pass' and its causative tacuachén 'deliver'. They show that tacuachén has achén as a component and achén is part of a complex form tacuachén.


(The default order of the fields in the dictionary puts components right after the lemma. I don't much like this, so I think I would edit the dictionary configuration to put them closer to the end.)
This isn't a problem with the design of FLEx, but one of practical implications for a person in language documentation is that sometimes the software gives you the ability to make more distinctions that are really needed for a dictionary and text collection. At least it gives me more options than I seem to need so far...
This isn't a problem with the design of FLEx, but one of practical implications for a person in language documentation is that sometimes the software gives you the ability to make more distinctions that are really needed for a dictionary and text collection. At least it gives me more options than I seem to need so far...